3D Gaussian Splatting for Real-Time Radiance Field Rendering
英文
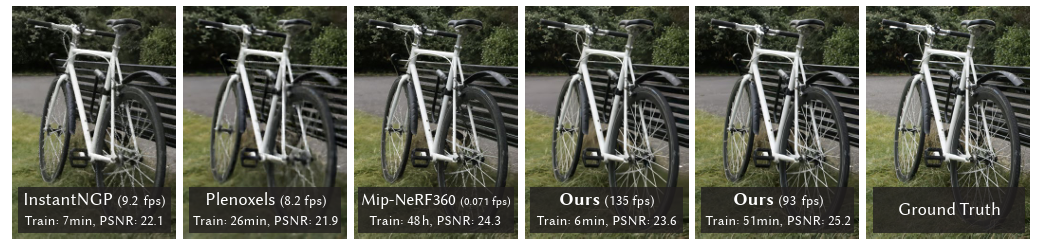
Fig. 1. Our method achieves real-time rendering of radiance fields with quality that equals the previous method with the best quality [Barron et al. 2022],while only requiring optimization times competitive with the fastest previous methods [Fridovich-Keil and Yu et al. 2022; Müller et al. 2022]. Key to this performance is a novel 3D Gaussian scene representation coupled with a real-time differentiable renderer, which offers significant speedup to both scene optimization and novel view synthesis. Note that for comparable training times to InstantNGP [Müller et al. 2022], we achieve similar quality to theirs; while this is the maximum quality they reach, by training for 51min we achieve state-of-the-art quality, even slightly better than Mip-NeRF360 [Barron et al. 2022].中文
图1. 我们的方法实现了辐射场的实时渲染,其质量与之前具有最佳质量的方法相当[Barron等人,2022年],同时只需要与最快的先前方法[Fridovich-Keil和Yu等人,2022年;Müller等人,2022年]竞争力相当的优化时间。这种性能的关键是一种新颖的3D高斯场景表示,与实时可微渲染器相结合,这显著加快了场景优化和新视角合成的速度。值得注意的是,与InstantNGP[Müller等人,2022年]相比,我们在类似的训练时间内实现了类似的质量;虽然这是他们达到的最高质量,但通过51分钟的训练,我们实现了最先进的质量,甚至略优于Mip-NeRF360[Barron等人,2022年]。optimization:最优化,最佳选择;comprtitive:竞争的,一样好的,couple:夫妻,结合,连接;speedup:加速;摘要
英文
Radiance Field methods have recently revolutionized novel-view synthesis of scenes captured with multiple photos or videos. However, achieving high visual quality still requires neural networks that are costly to train and render, while recent faster methods inevitably trade off speed for quality. For unbounded and complete scenes (rather than isolated objects) and 1080p resolution rendering, no current method can achieve real-time display rates.Weintroduce three key elements that allow us to achieve state-of-the-art visual quality while maintaining competitive training times and importantly allow high-quality real-time (≥ 30 fps) novel-view synthesis at 1080p resolution. First, starting from sparse points produced during camera calibration,we represent the scene with 3D Gaussians that preserve desirable properties of continuous volumetric radiance fields for scene optimization while avoiding unnecessary computation in empty space; Second, we perform interleaved optimization/density control of the 3D Gaussians, notably optimizing anisotropic covariance to achieve an accurate representation of the scene; Third, we develop a fast visibility-aware rendering algorithm that supports anisotropic splatting and both accelerates training and allows real time rendering. We demonstrate state-of-the-art visual quality and real-time rendering on several established datasets.中文
辐射场方法最近在多张照片或视频中捕获的场景的新视点合成方面取得了革命性的进展。然而,要实现高质量的视觉效果仍然需要昂贵的神经网络进行训练和渲染,而最近的快速方法不可避免地在速度和质量之间做出权衡。对于无界和完整的场景(而不仅仅是孤立的对象)以及1080p分辨率的渲染,目前没有一种方法可以实现实时的显示速率。我们引入了三个关键要素,使我们能够在保持竞争力的培训时间的同时实现最先进的视觉质量,并且重要的是允许在1080p分辨率下进行高质量的实时(≥ 30 fps)新视点合成。首先,从相机校准期间产生的稀疏点开始,我们使用3D高斯来表示场景,这些高斯保留了连续体积辐射场的理想特性,用于场景优化,同时避免了在空白空间中进行不必要的计算;其次,我们对3D高斯进行交替优化/密度控制,特别是优化各向异性协方差,以实现对场景的准确表示;第三,我们开发了一种快速的可见性感知渲染算法,支持各向异性的喷洒,并且既加速了训练,又允许实时渲染。我们在几个已建立的数据集上展示了最先进的视觉质量和实时渲染。 revolutionized:改变了;1 INTRODUCTION
英文
Meshes and points are the most common 3D scene representations becausetheyareexplicitandareagoodfitforfastGPU/CUDA-based rasterization. In contrast, recent Neural Radiance Field (NeRF) meth ods build on continuous scene representations, typically optimizing a Multi-Layer Perceptron (MLP) using volumetric ray-marching for novel-view synthesis of captured scenes. Similarly, the most efficient radiance field solutions to date build on continuous representations by interpolating values stored in, e.g., voxel [Fridovich-Keil and Yu et al. 2022] or hash [Müller et al. 2022] grids or points [Xu et al. 2022]. While the continuous nature of these methods helps optimization, the stochastic sampling required for rendering is costly and can result in noise. We introduce a new approach that combines the best of both worlds: our 3D Gaussian representation allows optimization with state-of-the-art (SOTA) visual quality and competitive training times, while our tile-based splatting solution ensures real-time ren dering at SOTA quality for 1080p resolution on several previously published datasets [Barron et al. 2022; Hedman et al. 2018; Knapitsch et al. 2017] (see Fig. 1).中文
网格和点云是最常见的3D场景表示方法,因为它们是显式的且适用于快速的GPU/CUDA渲染。然而,最近的神经辐射场(Neural Radiance Field,简称NeRF)方法采用了连续的场景表示,通常通过体积光线投射来优化多层感知器(Multi-Layer Perceptron,简称MLP),以实现对捕获场景的新视点合成。类似地,迄今为止最高效的辐射场解决方案也是基于连续表示的,例如在体素网格(如[Fridovich-Keil和Yu,2022])或哈希网格(如[Müller等,2022])中插值存储的值,或者基于点云(如[Xu等,2022])。虽然这些方法的连续性有助于优化,但渲染所需的随机采样成本高昂,可能会产生噪音。因此,我们引入了一种新方法,将两者的优点结合起来:我们的3D高斯表示在保持最先进的视觉质量和竞争性培训时间的同时,我们的基于瓦片的喷洒(splatting)解决方案确保了在1080p分辨率下以最先进的质量进行实时渲染,适用于几个先前发布的数据集英文
Our goal is to allow real-time rendering for scenes captured with multiple photos, and create the representations with optimization times as fast as the most efficient previous methods for typical real scenes. Recent methods achieve fast training [Fridovich-Keiland Yu et al. 2022; Müller et al. 2022], but struggle to achieve the visual quality obtained by the current SOTA NeRF methods, i.e., Mip-NeRF360 [Barron et al. 2022], which requires up to 48 hours of training time. The fast– but lower-quality– radiance field methods can achieve interactive rendering times depending on the scene (10-15 frames per second), but fall short of real-time rendering at high resolution.中文
我们的目标是实现对使用多张照片捕获的场景进行实时渲染,并在典型真实场景中以与最高效的先前方法相当的优化时间创建表示。最近的方法实现了快速训练1,但在视觉质量上仍无法达到当前SOTA NeRF方法(例如Mip-NeRF360 2),后者需要长达48小时的训练时间。虽然快速但质量较低的辐射场方法可以根据场景实现交互式渲染时间(每秒10-15帧),但无法实现高分辨率下的实时渲染英文
Our solution builds on three main components. We first intro duce 3D Gaussians as a flexible and expressive scene representation. Westart with the same input as previous NeRF-like methods, i.e., cameras calibrated with Structure-from-Motion (SfM) [Snavely et al. 2006] and initialize the set of 3D Gaussians with the sparse point cloud produced for free as part of the SfM process. In contrast to most point-based solutions that require Multi-View Stereo (MVS) data [Aliev et al. 2020; Kopanas et al. 2021; Rückert et al. 2022], we achieve high-quality results with only SfM points as input. Note that for the NeRF-synthetic dataset, our method achieves high qual ity even with random initialization. We show that 3D Gaussians are an excellent choice, since they are a differentiable volumetric representation, but they can also be rasterized very efficiently by projecting them to 2D, and applying standard 𝛼-blending, using an equivalent image formation model as NeRF. The second component of our method is optimization of the properties of the 3D Gaussians– 3Dposition, opacity 𝛼, anisotropic covariance, and spherical har monic (SH) coefficients– interleaved with adaptive density control steps, where we add and occasionally remove 3D Gaussians during optimization. The optimization procedure produces a reasonably compact, unstructured, and precise representation of the scene (1-5 million Gaussians for all scenes tested). The third and final element of our method is our real-time rendering solution that uses fast GPU sorting algorithms and is inspired by tile-based rasterization, fol lowing recent work [Lassner and Zollhofer 2021]. However, thanks to our 3D Gaussian representation, we can perform anisotropic splatting that respects visibility ordering– thanks to sorting and 𝛼 blending– and enable a fast and accurate backward pass by tracking the traversal of as many sorted splats as required.中文
我们的解决方案基于三个主要组件。首先,我们引入了3D高斯作为一种灵活且表达能力强的场景表示方法。我们从与之前类似NeRF方法相同的输入开始,即使用**结构运动(Structure-from-Motion,简称SfM)校准的相机,并使用SfM过程中免费生成的稀疏点云来初始化3D高斯集合。与大多数基于点的解决方案不同,后者需要多视图立体匹配(Multi-View Stereo,简称MVS)**数据,我们仅使用SfM点作为输入就可以获得高质量的结果。值得注意的是,在NeRF合成数据集上,即使随机初始化,我们的方法也可以实现高质量的结果。我们证明了3D高斯是一个出色的选择,因为它们是可微分的体积表示,但也可以通过将其投影到2D并应用标准的𝛼混合(alpha-blending)来高效地进行光栅化,使用与NeRF相同的等效图像形成模型。我们方法的第二个组成部分是对3D高斯的属性进行优化,包括3D位置、不透明度𝛼、各向异性协方差和球谐(SH)系数,这些属性与自适应密度控制步骤交替进行,我们在优化过程中添加并偶尔移除3D高斯。优化过程产生了一个合理紧凑、非结构化且精确的场景表示(在所有测试场景中,使用了100-500万个高斯)。我们方法的第三个和最后一个元素是我们的实时渲染解决方案,它使用快速的GPU排序算法,受到基于瓦片的光栅化的启发,遵循最近的工作1。然而,由于我们的3D高斯表示,我们可以执行各向异性喷洒,以遵守排序和𝛼混合,同时通过跟踪所需数量的已排序喷洒的遍历来实现快速且准确的反向传递。英文
To summarize, we provide the following contributions: • Theintroductionofanisotropic3DGaussiansasahigh-quality, unstructured representation of radiance fields. • An optimization method of 3D Gaussian properties, inter leaved with adaptive density control that creates high-quality representations for captured scenes. • Afast, differentiable rendering approach for the GPU, which is visibility-aware, allows anisotropic splatting and fast back propagation to achieve high-quality novel view synthesis. Our results on previously published datasets show that we can opti mize our 3D Gaussians from multi-view captures and achieve equal or better quality than the best quality previous implicit radiance f ield approaches. We also can achieve training speeds and quality similar to the fastest methods and importantly provide the first real-time rendering with high quality for novel-view synthesis中文
总结一下,我们提供了以下贡献:- 引入各向异性3D高斯作为辐射场的高质量、非结构化表示方法。
- 优化3D高斯属性的方法,与自适应密度控制交替进行,为捕获的场景创建高质量的表示。
- 基于GPU的快速、可微分渲染方法,具有可见性感知性,支持各向异性喷洒,并通过跟踪所需数量的已排序喷洒实现快速且准确的反向传递。
我们在先前发布的数据集上的结果表明,我们可以从多视图捕获中优化我们的3D高斯,并获得与最佳隐式辐射场方法相等或更好的质量。我们还可以实现与最快方法相似的训练速度和质量,并且重要的是首次提供了具有高质量的实时渲染的新视点合成。
2 RELATEDWORK
英文
We first briefly overview traditional reconstruction, then discuss
point-based rendering and radiance field work, discussing their similarity; radiance fields are a vast area, so we focus only ondirectly
related work. For complete coverage of the field, please see the
excellent recent surveys [Tewari et al. 2022; Xie et al. 2022].
中文
我们首先简要回顾传统的重建方法,然后讨论基于点的渲染和辐射场工作,探讨它们的相似性;辐射场是一个广阔的领域,因此我们只关注直接相关的工作。要全面了解该领域,请参阅[Tewari et al. 2022; Xie et al. 2022]的优秀最新综述。2.1 Traditional Scene Reconstruction and Rendering
英文
The first novel-view synthesis approaches were based on light fields, f irst densely sampled [Gortler et al. 1996; Levoy and Hanrahan 1996] then allowing unstructured capture [Buehler et al. 2001]. The advent of Structure-from-Motion (SfM) [Snavely et al. 2006] enabled an entire new domain where a collection of photos could be used to synthesize novel views. SfM estimates a sparse point cloud during camera calibration, that was initially used for simple visualization of 3D space. Subsequent multi-view stereo (MVS) produced im pressive full 3D reconstruction algorithms over the years [Goesele et al. 2007], enabling the development of several view synthesis algorithms [Chaurasia et al. 2013; Eisemann et al. 2008; Hedman et al. 2018; Kopanas et al. 2021]. All these methods re-project and blend the input images into the novel view camera, and use the geometry to guide this re-projection. These methods produced ex cellent results in many cases, but typically cannot completely re cover from unreconstructed regions, or from “over-reconstruction”, when MVS generates inexistent geometry. Recent neural render ing algorithms [Tewari et al. 2022] vastly reduce such artifacts and avoid the overwhelming cost of storing all input images on the GPU, outperforming these methods on most fronts.中文
第一个新颖的视图合成方法基于光场,首先是密集采样 [Gortler 等人。 1996; Levoy 和 Hanrahan 1996] 然后允许非结构化捕获 [Buehler 等人。 2001]。运动结构 (SfM) 的出现 [Snavely 等人。 2006]启用了一个全新的领域,可以使用一组照片来合成新颖的视图。 SfM 在相机校准期间估计稀疏点云,最初用于 3D 空间的简单可视化。随后的多视图立体 (MVS) 多年来产生了令人印象深刻的全 3D 重建算法 [Goesele 等人。 2007],使得多种视图合成算法的开发成为可能[Chaurasia 等人。 2013年;艾斯曼等人。 2008年;赫德曼等人。 2018;科帕纳斯等人。 2021]。所有这些方法都将输入图像重新投影并混合到新颖的视图相机中,并使用几何形状来指导这种重新投影。这些方法在许多情况下产生了出色的结果,但当 MVS 生成不存在的几何体时,通常无法从未重建区域或“过度重建”中完全恢复。最近的神经渲染算法 [Tewari 等人。 2022]大大减少了此类伪影,并避免了将所有输入图像存储在 GPU 上的巨大成本,在大多数方面都优于这些方法。2.2 Neural Rendering and Radiance Fields
英文
Deeplearning techniques were adopted early for novel-view synthe sis [Flynn et al. 2016; Zhou et al. 2016]; CNNs were used to estimate blendingweights[Hedmanetal.2018],orfortexture-spacesolutions [Riegler and Koltun 2020; Thies et al. 2019]. The use of MVS-based geometry is a major drawback of most of these methods; in addition, the use of CNNs for final rendering frequently results in temporal f lickering. Volumetric representations for novel-view synthesis were ini tiated by Soft3D [Penner and Zhang 2017]; deep-learning tech niques coupled with volumetric ray-marching were subsequently proposed[Henzleretal.2019;Sitzmannetal.2019]buildingonacon tinuous differentiable density field to represent geometry. Rendering using volumetric ray-marching has a significant cost due to the large number of samples required to query the volume. Neural Radiance Fields (NeRFs) [Mildenhall et al. 2020] introduced importance sam pling and positional encoding to improve quality, but used a large Multi-Layer Perceptron negatively affecting speed. The success of NeRFhasresulted in anexplosion of follow-up methods that address quality and speed, often by introducing regularization strategies; the current state-of-the-art in image quality for novel-view synthesis is Mip-NeRF360 [Barron et al. 2022]. While the rendering quality is outstanding, training and rendering times remain extremely high; we are able to equal or in some cases surpass this quality while providing fast training and real-time rendering.中文
深度学习技术早期被用于新视角合成¹²。卷积神经网络(CNN)被用于估计融合权重³,或者用于纹理空间解决方案⁴。然而,大多数这些方法都使用基于多视图立体几何的表示,这是一个主要的缺点。此外,使用CNN进行最终渲染通常会导致时间上的闪烁。体素表示用于新视角合成的初始方法是Soft3D⁵。随后,深度学习技术与体素光线投射相结合,构建了一个连续可微的密度场来表示几何形状⁶。使用体素光线投射进行渲染由于需要大量样本来查询体积而成本高昂。神经辐射场(NeRF)⁷ 引入了重要性采样和位置编码以提高质量,但使用了大型多层感知器(MLP),从而影响了速度。NeRF的成功导致了一系列后续方法的涌现,这些方法通常通过引入正则化策略来解决质量和速度问题。目前,新视角合成的图像质量的最新技术是Mip-NeRF360⁸。虽然渲染质量出色,但训练和渲染时间仍然非常长。我们能够在提供快速训练和实时渲染的同时,达到或甚至超越这一质量水平。
英文
The most recent methods have focused on faster training and/or rendering mostly by exploiting three design choices: the use of spa tial data structures to store (neural) features that are subsequently interpolated during volumetric ray-marching, different encodings,and MLP capacity. Such methods include different variants of space discretization [Chen et al. 2022b,a; Fridovich-Keil and Yu et al. 2022; Garbin et al. 2021; Hedman et al. 2021; Reiser et al. 2021; Takikawa et al. 2021; Wu et al. 2022; Yu et al. 2021], codebooks [Takikawa et al. 2022], and encodings such as hash tables [Müller et al. 2022], allowing the use of a smaller MLP or foregoing neural networks completely [Fridovich-Keil and Yu et al. 2022; Sun et al. 2022]. Mostnotable of these methods are InstantNGP[Müller et al. 2022] which uses a hash grid and an occupancy grid to accelerate compu tation and a smaller MLP to represent density and appearance; and Plenoxels [Fridovich-Keil and Yu et al. 2022] that use a sparse voxel grid to interpolate a continuous density field, and are able to forgo neural networks altogether. Both rely on Spherical Harmonics: the former to represent directional effects directly, the latter to encode its inputs to the color network. While both provide outstanding results, these methods can still struggle to represent empty space effectively, depending in part on the scene/capture type. In addition, image quality is limited in large part by the choice of the structured grids used for acceleration, and rendering speed is hindered by the need to query many samples for a given ray-marching step. The un structured, explicit GPU-friendly 3D Gaussians weuseachievefaster rendering speed and better quality without neural components.中文
最近的方法主要集中在更快的训练和/或渲染,主要通过利用三个设计选择来实现:使用空间数据结构来存储(神经)特征,随后在体素光线投射期间进行插值,不同的编码和多层感知器(MLP)容量。这些方法包括不同变体的空间离散化⁵⁶⁷⁸ ,码本,以及哈希表等编码,允许使用较小的MLP或完全放弃神经网络 。 其中最值得注意的方法包括InstantNGP,它使用哈希网格和占用网格来加速计算,并使用较小的MLP来表示密度和外观;以及Plenoxels,它使用稀疏体素网格来插值连续的密度场,并且能够完全放弃神经网络。这两种方法都依赖于球谐函数:前者直接表示方向效应,后者将其输入编码到颜色网络中。虽然两者都提供了出色的结果,但这些方法在一定程度上仍然难以有效地表示空白空间,这部分取决于场景/捕捉类型。此外,图像质量在很大程度上受到用于加速的结构化网格的选择的限制,而渲染速度受到查询给定光线投射步骤的许多样本的需求的影响。我们使用的非结构化、明确的GPU友好的3D高斯函数实现了更快的渲染速度和更好的质量,而无需神经组件。2.3 Point-Based Rendering and Radiance Fields
英文
Point-based methods efficiently render disconnected and unstruc tured geometry samples (i.e., point clouds) [Gross and Pfister 2011]. In its simplest form, point sample rendering [Grossman and Dally 1998] rasterizes an unstructured set of points with a fixed size, for whichit mayexploitnatively supported point types of graphics APIs [Sainz and Pajarola 2004] or parallel software rasterization on the GPU[Laine and Karras 2011; Schütz et al. 2022]. While true to the underlying data, point sample rendering suffers from holes, causes aliasing, and is strictly discontinuous. Seminal work on high-quality point-based rendering addresses these issues by “splatting” point primitives with an extent larger than a pixel, e.g., circular or elliptic discs, ellipsoids, or surfels [Botsch et al. 2005; Pfister et al. 2000; Ren et al. 2002; Zwicker et al. 2001b]. Therehasbeenrecentinterestindifferentiable point-based render ing techniques [Wiles et al. 2020; Yifan et al. 2019]. Points have been augmented with neural features and rendered using a CNN [Aliev et al. 2020; Rückert et al. 2022] resulting in fast or even real-time view synthesis; however they still depend on MVS for the initial geometry, and as such inherit its artifacts, most notably over- or under-reconstruction in hard cases such as featureless/shiny areas or thin structures.中文
点云方法高效地渲染了不连续和非结构化的几何样本(即点云)¹。在其最简单的形式中,点样本渲染²将一个非结构化的点集进行光栅化,其大小固定,可以利用图形API的本地支持的点类型³,或者在GPU上进行并行软件光栅化⁴。虽然点样本渲染忠实于底层数据,但它存在孔洞、导致混叠,并且严格不连续。关于高质量点云渲染的开创性工作通过“喷洒”比像素大的点基元来解决这些问题,例如圆形或椭圆形的圆盘、椭球体或surfels⁵ 。近年来,不可微分的基于点的渲染技术引起了人们的兴趣 。点被增强为具有神经特征,并使用CNN进行渲染,从而实现了快速甚至实时的视图合成;然而,它们仍然依赖于多视图立体几何(MVS)来获得初始几何形状,并因此继承了其众所周知的缺陷,尤其是在无特征/闪亮区域或薄结构等复杂情况下的过度或不足重建。
中英文
Point-based 𝛼-blending and NeRF-style volumetric rendering share essentially the same image formation model. Specifically, the color 𝐶 is given by volumetric rendering along a ray:点云方法的𝛼混合和NeRF风格的体积渲染实际上共享相同的图像形成模型。具体而言,颜色𝐶是通过沿着一条射线进行体积渲染来确定的:
$\ C = \sum_{i=1}^{N} \left( T_i (1 - \exp(-\sigma_i \delta_i))c_i \right) \quad(1)$
其中:
$ T_i = \exp \left( -\sum_{j=1}^{i-1} \sigma_j \delta_j \right)$
- $ N $表示沿射线的样本数。
- $ T_i $ 是透射率。
- $ sigma_i $ 表示介质的密度。
- $ delta_i $表示沿射线的间隔。
- $ c_i $对应于每个采样点的颜色。
where samples of density 𝜎, transmittance𝑇, and color c are taken
along the ray with intervals 𝛿𝑖. This can be re-written as
在沿着射线以间隔𝛿𝑖取样密度𝜎、透射率𝑇和颜色𝑐的样本。这可以重新表述为
$ \sum_{i=1}^{N} T_i \alpha_i c_i \quad(2)$
其中:
- $ \alpha_i = (1 - \exp(-\sigma_i \delta_i)) $
- $ T_i = \prod_{j=1}^{i-1} (1 - \alpha_i)\ $
Atypical neural point-based approach (e.g., [Kopanas et al. 2022,
2021]) computes the color𝐶 of a pixel by blending N ordered points
overlapping the pixel:
典型的神经点云方法(例如,[Kopanas等人,2022年;2021年])通过混合重叠在像素上的N个有序点来计算像素的颜色𝐶:
$ C = \sum_{i \in N} \left( c_i \alpha_i \prod_{j=1}^{i-1} (1 - \alpha_j) \right) \quad(3)$
where c𝑖 is the color of each point and 𝛼𝑖 is given by evaluating a
2D Gaussian with covariance Σ [Yifan et al. 2019] multiplied with a
learned per-point opacity.
其中,$c_i$ 表示每个点的颜色,$alpha_i$ 是通过评估具有协方差 $\Sigma$ 的二维高斯函数并乘以每个点的透明度得出的。
英文
From Eq. 2 and Eq. 3, we can clearly see that the image formation model is the same. However, the rendering algorithm is very differ ent. NeRFs are a continuous representation implicitly representing empty/occupied space; expensive random sampling is required to f ind the samples in Eq. 2 with consequent noise and computational expense. In contrast, points are an unstructured, discrete represen tation that is flexible enough to allow creation, destruction, and displacement of geometry similar to NeRF. This is achieved by opti mizing opacity and positions, as shown by previous work [Kopanas et al. 2021], while avoiding the shortcomings of a full volumetric representation. Pulsar [Lassner and Zollhofer 2021] achieves fast sphere rasteri zation which inspired our tile-based and sorting renderer. However, given the analysis above, we want to maintain (approximate) con ventional 𝛼-blending on sorted splats to have the advantages of vol umetric representations: Our rasterization respects visibility order in contrast to their order-independent method. In addition, we back propagate gradients on all splats in a pixel and rasterize anisotropic splats. These elements all contribute to the high visual quality of our results (see Sec. 7.3). In addition, previous methods mentioned above also use CNNs for rendering, which results in temporal in stability. Nonetheless, the rendering speed of Pulsar [Lassner and Zollhofer 2021] and ADOP[Rückertetal.2022]servedasmotivation to develop our fast rendering solution.中文
从公式2和公式3中,我们可以清楚地看到图像形成模型是相同的。然而,渲染算法却非常不同。NeRF(神经辐射场)是一种连续表示,隐式地表示了空/占用空间;在公式2中,需要昂贵的随机采样,从而产生噪音和计算开销。相比之下,点云是一种非结构化、离散的表示,足够灵活,可以允许类似NeRF的几何形状的创建、销毁和位移。这是通过优化不透明度和位置实现的,正如之前的工作所示[Kopanas等人,2021年],同时避免了完整体积表示的缺点。Pulsar [Lassner和Zollhofer,2021年]实现了快速的球体光栅化,这启发了我们基于瓦片和排序的渲染器。然而,鉴于上述分析,我们希望保持对排序的斑点进行(近似)常规𝛼混合,以具有体积表示的优势:我们的光栅化与其无序方法相比尊重可见性顺序。此外,我们在像素中反向传播所有斑点的梯度,并光栅化各向异性斑点。所有这些因素都有助于我们结果的高视觉质量(请参阅第7.3节)。此外,上述提到的先前方法还使用CNN进行渲染,这导致了时间上的不稳定性。尽管如此,Pulsar [Lassner和Zollhofer,2021年]和ADOP[Rückertetal.2022]的渲染速度成为我们开发快速渲染解决方案的动力。🌟
英文
While focusing on specular effects, the diffuse point-based ren dering track of Neural Point Catacaustics [Kopanas et al. 2022] overcomes this temporal instability by using an MLP, but still re quired MVS geometry as input. The most recent method [Zhang et al. 2022] in this category does not require MVS, and also uses SH for directions; however, it can only handle scenes of one object and needs masks for initialization. While fast for small resolutions and low point counts, it is unclear how it can scale to scenes of typical datasets [Barron et al. 2022; Hedman et al. 2018; Knapitsch et al. 2017]. We use 3D Gaussians for a more flexible scene rep resentation, avoiding the need for MVS geometry and achieving real-time rendering thanks to our tile-based rendering algorithm for the projected Gaussians.A recent approach [Xu et al. 2022] uses points to represent a radiance field with a radial basis function approach. They employ point pruning and densification techniques during optimization, but use volumetric ray-marching and cannot achieve real-time display rates. In the domain of human performance capture, 3D Gaussians have been used to represent captured human bodies [Rhodin et al. 2015; Stoll et al. 2011]; more recently they have been used with volumetric ray-marching for vision tasks [Wang et al. 2023]. Neural volumetric primitives have been proposed in a similar context [Lombardi et al. 2021]. While these methods inspired the choice of 3D Gaussians as our scene representation, they focus on the specific case of recon structing and rendering a single isolated object (a human body or face), resulting in scenes with small depth complexity. In contrast, our optimization of anisotropic covariance, our interleaved optimiza tion/density control, and efficient depth sorting for rendering allow us to handle complete, complex scenes including background, both indoors and outdoors and with large depth complexity.中文
在关注镜面效果时,神经点光线追踪的漫反射点云渲染跟踪(例如Neural Point Catacaustics [Kopanas等人,2022年])通过使用MLP(多层感知器)克服了时间上的不稳定性,但仍需要多视图立体几何(MVS)作为输入。在这一类别中,最近的方法[Zhang等人,2022年]不需要MVS,还使用了球谐函数(SH)来表示方向;然而,它只能处理一个物体的场景,并且需要用于初始化的遮罩。虽然对于小分辨率和低点数的情况下速度很快,但它尚不清楚如何扩展到典型数据集的场景[Barron等人,2022年;Hedman等人,2018年;Knapitsch等人,2017年]。我们使用三维高斯函数来实现更灵活的场景表示,避免了对MVS几何的需求,并通过我们的基于瓦片的渲染算法实现了投影高斯函数的实时渲染。最近的一种方法[Xu等人,2022年]使用点来表示具有径向基函数方法的辐射场。他们在优化过程中采用了点修剪和加密技术,但使用了体积光线行进,并且无法实现实时显示速率。
在人体性能捕捉领域,三维高斯函数已被用于表示捕捉到的人体[Rhodin等人,2015年;Stoll等人,2011年];最近,它们已与体积光线行进一起用于视觉任务[Wang等人,2023年]。神经体积原语在类似的背景下也被提出[Lombardi等人,2021年]。尽管这些方法启发了我们选择三维高斯函数作为场景表示,但它们专注于重建和渲染单个孤立对象(例如人体或面部),从而导致深度复杂度较小的场景。相比之下,我们对各向异性协方差的优化、交错的优化/密度控制以及用于渲染的高效深度排序使我们能够处理完整、复杂的场景,包括室内外背景,以及具有大深度复杂度的场景。
3 OVERVIEW
英文
The input to our method is a set of images of a static scene, together with the corresponding cameras calibrated by SfM [Schönberger and Frahm 2016] which produces a sparse point cloud as a side effect. From these points we create a set of 3D Gaussians (Sec. 4), defined by a position (mean), covariance matrix and opacity 𝛼, that allows a very flexible optimization regime. This results in a reason ably compact representation of the 3D scene, in part because highly anisotropic volumetric splats can be used to represent fine structures compactly. The directional appearance component (color) of the radiance field is represented via spherical harmonics (SH), following standard practice [Fridovich-Keil and Yu et al. 2022; Müller et al. 2022]. Our algorithm proceeds to create the radiance field represen tation (Sec. 5) via a sequence of optimization steps of 3D Gaussian parameters, i.e., position, covariance, 𝛼 and SH coefficients inter leaved with operations for adaptive control of the Gaussian density. The key to the efficiency of our method is our tile-based rasterizer (Sec. 6) that allows 𝛼-blending of anisotropic splats, respecting visi bility order thanks to fast sorting. Out fast rasterizer also includes a fast backward pass by tracking accumulated 𝛼 values, without a limit on the number of Gaussians that can receive gradients. The overview of our method is illustrated in Fig. 2.中文
我们方法的输入是一组静态场景的图像,以及由SfM(结构光束法)校准的相应相机,这会产生一个稀疏的点云作为副作用。从这些点中,我们创建了一组三维高斯函数(第4节),由位置(均值)、协方差矩阵和不透明度𝛼定义,从而实现了非常灵活的优化方案。这导致了对3D场景的相对紧凑的表示,部分原因是高度各向异性的体积斑点可以紧凑地表示精细结构。辐射场的方向外观成分(颜色)通过球谐函数(SH)表示,遵循标准做法[Fridovich-Keil和Yu等人,2022年;Müller等人,2022年]。我们的算法通过一系列对3D高斯参数的优化步骤(即位置、协方差、𝛼和SH系数)来创建辐射场表示(第5节),并与自适应控制高斯密度的操作交错进行。我们方法效率的关键在于我们基于瓦片的光栅化器(第6节),它允许各向异性斑点的𝛼混合,通过快速排序尊重可见性顺序。我们的快速光栅化器还包括通过跟踪累积的𝛼值进行快速反向传播,而不限制可以接收梯度的高斯数量。我们方法的概述如图2所示。4 DIFFERENTIABLE 3D GAUSSIAN SPLATTING
中英文
Our goal is to optimize a scene representation that allows high quality novel view synthesis, starting from a sparse set of (SfM) points without normals. To do this, we need a primitive that inherits the properties of differentiable volumetric representations, while at the same time being unstructured and explicit to allow very fast rendering. We choose 3D Gaussians, which are differentiable and can be easily projected to 2D splats allowing fast 𝛼-blending for rendering. Our representation has similarities to previous methods that use 2D points [Kopanas et al. 2021; Yifan et al. 2019] and assume each point is a small planar circle with a normal. Given the extreme sparsity of SfM points it is very hard to estimate normals. Similarly, optimizing very noisy normals from such an estimation would be very challenging. Instead, we model the geometry as a set of 3D Gaussians that do not require normals. Our Gaussians are defined by a full 3D covariance matrix Σ defined in world space [Zwicker et al. 2001a] centered at point (mean) 𝜇:我们的目标是优化一种场景表示,允许从稀疏的(SfM)点集开始进行高质量的新视角合成,而无需法线。为了实现这一目标,我们需要一种既具有可微分体积表示的特性,同时又是非结构化且明确的,以便实现非常快速的渲染。我们选择了三维高斯函数,它们是可微分的,并且可以轻松投影到二维斑点,从而实现了快速的𝛼混合渲染。
我们的表示与之前使用2D点的方法[Kopanas等人,2021年;Yifan等人,2019年]有相似之处,并假设每个点是一个带有法线的小平面圆。鉴于SfM点的极端稀疏性,很难估计法线。类似地,从这种估计中优化非常嘈杂的法线将是非常具有挑战性的。因此,我们将几何形状建模为一组不需要法线的三维高斯函数。我们的高斯函数由在世界空间中定义的完整三维协方差矩阵Σ定义,以点(均值)𝜇为中心[Zwicker等人,2001a年]:
$G(x) = e^{-\frac{1}{2} (x)^T \Sigma^{-1} (x)}\quad(4)$
This Gaussian function is multiplied by $\alpha$ in our blending process.
这个高斯函数在我们的混合过程中与 $\alpha$ 相乘
However,we need to project our 3D Gaussians to 2D for rendering.
Zwicker et al. [2001a] demonstrate how to do this projection to image space. Given a viewing transformation 𝑊 the covariance matrix Σ′ in camera coordinates is given as follows:
然而,我们需要将我们的三维高斯函数投影到二维以进行渲染。Zwicker等人[2001a]演示了如何将其投影到图像空间。给定一个视图变换𝑊,协方差矩阵Σ′在相机坐标中定义如下:
$ \Sigma’ = J W \Sigma W^T J^T \quad(5)$
where 𝐽 is the Jacobian of the affine approximation of the projective
transformation. Zwicker et al. [2001a] also show that if we skip the
third row and column of Σ′, we obtain a 2×2 variance matrix with
the same structure and properties as if we would start from planar
points with normals, as in previous work [Kopanas et al. 2021].
其中,𝐽是投影变换的仿射近似的雅可比矩阵。Zwicker等人[2001a]还表明,如果我们跳过Σ′的第三行和第三列,我们将获得一个2×2的方差矩阵,其结构和性质与我们从具有法线的平面点开始的情况相同,就像之前的工作[Kopanas等人,2021年]一样
An obvious approach would be to directly optimize the covariance
matrix Σ to obtain 3D Gaussians that represent the radiance field.
However, covariance matrices have physical meaning only when
they are positive semi-definite. For our optimization of all our pa
rameters, we use gradient descent that cannot be easily constrained
to produce such valid matrices, and update steps and gradients can
very easily create invalid covariance matrices.
一个明显的方法是直接优化协方差矩阵Σ,以获得表示辐射场的三维高斯函数。然而,协方差矩阵只有在它们是半正定的时候才具有物理意义。对于我们所有参数的优化,我们使用梯度下降,很难约束其产生这样有效的矩阵,而且更新步骤和梯度很容易产生无效的协方差矩阵。
As a result, we opted for a more intuitive, yet equivalently ex
pressive representation for optimization. The covariance matrix Σ
of a 3D Gaussian is analogous to describing the configuration of an
ellipsoid. Given a scaling matrix 𝑆 and rotation matrix 𝑅, we can
f
ind the corresponding Σ:
因此,我们选择了一种更直观但同样表达能力的优化表示。三维高斯函数的协方差矩阵Σ类似于描述椭球体的配置。给定一个缩放矩阵𝑆和旋转矩阵𝑅,我们可以找到相应的Σ:
$ \Sigma = R S S^T R^T \quad(6) $
To allow independent optimization of both factors, we store them
separately: a 3D vector 𝑠 for scaling and a quaternion 𝑞 to represent
rotation. These canbetrivially converted to their respective matrices
and combined, making sure to normalize 𝑞 to obtain a valid unit
quaternion.
为了允许独立优化这两个因素,我们将它们分开存储:一个用于缩放的三维向量𝑠和一个用于表示旋转的四元数𝑞。这些可以轻松地转换为各自的矩阵并组合,确保归一化𝑞以获得有效的单位四元数。
To avoid significant overhead due to automatic differentiation
during training, we derive the gradients for all parameters explicitly.
Details of the exact derivative computations are in appendix A.
为了避免由于训练过程中的自动微分而产生的显著开销,我们明确地计算了所有参数的梯度。关于精确导数计算的详细信息请参见附录A。
This representation of anisotropic covariance– suitable for op
timization– allows us to optimize 3D Gaussians to adapt to the
geometry of different shapes in captured scenes, resulting in a fairly
compact representation. Fig. 3 illustrates such cases.
这种适用于优化的各向异性协方差表示使我们能够优化三维高斯函数以适应捕获场景中不同形状的几何结构,从而得到相对紧凑的表示。图3说明了这样的情况。
5 OPTIMIZATION WITH ADAPTIVE DENSITY CONTROL OF 3D GAUSSIANS
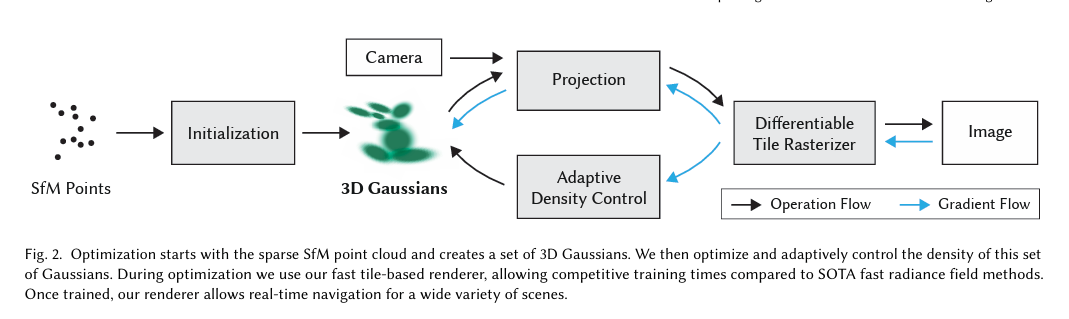
图2. 优化从稀疏的SfM点云开始,创建了一组3D高斯函数。然后,我们对这组高斯函数的密度进行优化和自适应控制。在优化过程中,我们使用了快速的基于瓦片的渲染器,使其在训练时间上具有与SOTA快速辐射场方法相竞争的优势。一旦训练完成,我们的渲染器允许对各种场景进行实时导航.
Projection:投射;Adaptive Density Control:自适应密度控制;可微分瓦片光栅化器(Differentiable Tile Rasterizer);操作流程(Operation Flow);梯度流(Gradient Flow)

图3。我们在优化后将3D高斯函数缩小60%(最右侧)。这清楚地展示了经过优化后紧凑地表示复杂几何形状的3D高斯函数的各向异性形状。左侧是实际渲染的图像。
英文
The core of our approach is the optimization step, which creates a dense set of 3D Gaussians accurately representing the scene for free-view synthesis. In addition to positions 𝑝, 𝛼, and covariance Σ, we also optimize SH coefficients representing color 𝑐 of each Gaussian to correctly capture the view-dependent appearance of the scene. The optimization of these parameters is interleaved with steps that control the density of the Gaussians to better represent the scene.中文
我们方法的核心是优化步骤,它创建了一组密集的三维高斯函数,准确地表示了用于自由视角合成的场景。除了位置𝑝、𝛼和协方差Σ之外,我们还优化了表示每个高斯函数颜色𝑐的球谐系数,以正确捕捉场景的视角相关外观。这些参数的优化与控制高斯函数密度的步骤交错进行,以更好地表示场景。5.1 Optimization
英文
The optimization is based on successive iterations of rendering and comparing the resulting image to the training views in the captured dataset. Inevitably, geometry may be incorrectly placed due to the ambiguities of 3D to 2D projection. Our optimization thus needs to be able to create geometry and also destroy or move geometry if it has been incorrectly positioned. The quality of the parameters of the covariances of the 3D Gaussians is critical for the compactness of the representation since large homogeneous areas can be captured with a small number of large anisotropic Gaussians. Weuse Stochastic Gradient Descent techniques for optimization, taking full advantage of standard GPU-accelerated frameworks, and the ability to add custom CUDA kernels for some operations, following recent best practice [Fridovich-Keil and Yu et al. 2022; Sun et al. 2022]. In particular, our fast rasterization (see Sec. 6) is critical in the efficiency of our optimization, since it is the main computational bottleneck of the optimization中文
优化基于连续的渲染和将生成的图像与捕获数据集中的训练视图进行比较的迭代。由于3D到2D投影的不确定性,几何体可能被错误地放置。因此,我们的优化需要能够创建几何体,同时如果其位置不正确,还可以销毁或移动几何体。3D高斯函数的协方差参数的质量对于表示的紧凑性至关重要,因为大均匀区域可以用少量大型各向异性高斯函数捕获。我们使用随机梯度下降技术进行优化,充分利用标准的GPU加速框架,并且可以为某些操作添加自定义的CUDA内核,遵循最近的最佳实践¹²。特别是,我们快速的光栅化(见第6节)对于我们的优化效率至关重要,因为它是优化的主要计算瓶颈。

